



![[AWS] Lambda Concepts Essentials](https://cdn.hashnode.com/res/hashnode/image/upload/v1714021599039/33c56f2b-6d1f-4f4d-af09-a2a68403c8d9.png?w=1600&h=840&fit=crop&crop=entropy&auto=compress,format&format=webp)
Table of contents
- Inception
- Overview
- Function
- Lambda Function handler in Python
- Lambda Function Arguments
- Utilizing event Argument
- Utilizing context Argument
- Environment Variables
- Naming
- Synchronous invocation
- Asynchronous invocation
- Runtime dependencies in Python
- Creating a .zip deployment package with no dependencies
- Creating a .zip deployment package with dependencies
- Working with Lambda layers
- Dependency search path and runtime-included libraries
- Lambda function logging in Python
- Viewing logs in CloudWatch console
Inception
Hello everyone, This article is part of The Terraform + AWS series, And it's not depend on any previous articles, I use this series to publish out AWS + Terraform Projects & Knowledge.
Overview
Hello Gurus, AWS Lambda is a compute service that lets you run code without provisioning or managing servers, Lambda runs your code on a high-availability compute infrastructure and performs all of the administration of the compute resources, Enables us to type-down your code that precisely meet your needs regardless of the servers management.
Today's Article will attempt to cover the most important Lambda concepts, which have been thoroughly defined and explained in AWS documentation. Here, we will provide a recap of Lambda's core concepts, which I am confident will help you get started with Lambda.
Function
A function is a resource that you can invoke to run your code in Lambda. A function has code to process the events that you pass into the function or that other AWS services send to the function.
Consider a lambda function as you would a regular Python function: you define the function and then specify the values it will accept when called.
Lambda Function handler in Python
The Lambda function handler is the method in your function code that processes events. When your function is invoked, Lambda runs the handler method. Your function runs until the handler returns a response, exits, or times out.
Lambda functions have a constant and predefined structure, knows as the handler function, which accept predefined arguments, specifically (event, context). These will covered shortly, you can disregard the function arguments and process to write your regular code within the handler function.
You can use the following general syntax when creating a function handler in Python:
def handler_name(event, context):
...
return some_value
Lambda Function Arguments
When Lambda invokes your function handler, the Lambda runtime passes two arguments to the function handler:
The first argument is the event object. An event is a JSON-formatted document that contains data for a Lambda function to process. The Lambda runtime converts the event to an object and passes it to your function code.
The second argument is the context object**.**A context object is passed to your function by Lambda at runtime. This object provides methods and properties that provide information about the invocation, function, and runtime environment.
Utilizing event Argument
An event is a JSON-formatted document containing data for a Lambda function to process. using event arguments to pass data within your function to process, which can be provided manually or by another AWS service. Additionally, an event is not mandatory; if it is not specified in your code, the function will still execute without processing any data.
Example
Open-up your AWS console, Navigate to lambda resource, Press Create a function.
At function name filed type "demo_function_name"
At Runtime filed specify "Python3.12" and leave the rest as default, Then press create.
At your function, Scroll-down at Code source section, Replace the provided code with the below instead
def lambda_handler(event, context):
message = 'Hello {} {}!'.format(event['first_name'], event['last_name'])
return {
'message' : message
}
Press Deploy, wait until your new code is deployed.
Press Test, This will open-up a new windows which ask you to provide your event values that the function will process.
At Event name filed type "event_one"
At Event JSON filed pass the first_name and last_name values in JSON-formatted as following
{
"first_name": "Mohamed",
"last_name": "eraki"
}
Leave the rest as default, Then Save.
Press Test again, This will open a new tab have the returned values as the following
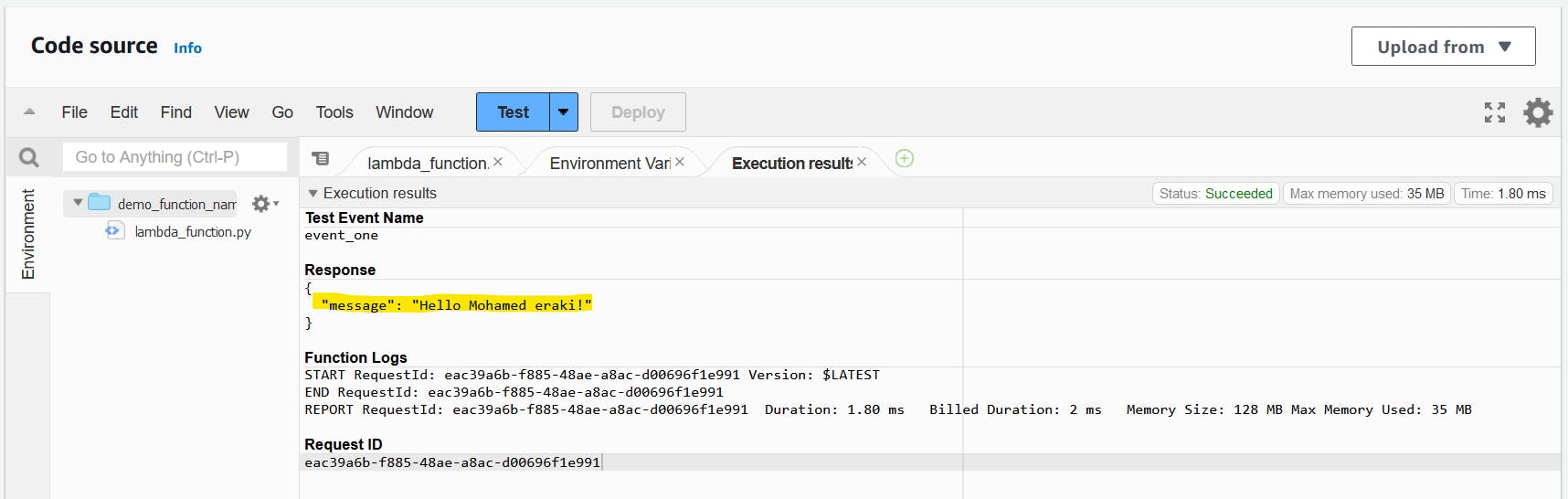
Now we understand how to use the event argument to pass data, which I think is very straightforward and uses native Python syntax.
Utilizing context Argument
A context object is passed to your function by Lambda at runtime. This object provides methods and properties that provide information about the invocation, function, and runtime environment. Which means you didn't pass any values to the context argument, it handles by lambda.
When Lambda runs your function, it passes a context object to the handler. This object provides methods and properties that provide information about the invocation, function, and execution environment. For more information on how the context object is passed to the function handler, see Lambda function handler in Python.
Context methods
get_remaining_time_in_millis– Returns the number of milliseconds left before the execution times out.
Context properties
function_name– The name of the Lambda function.function_version– The version of the function.invoked_function_arn– The Amazon Resource Name (ARN) that's used to invoke the function. Indicates if the invoker specified a version number or alias.memory_limit_in_mb– The amount of memory that's allocated for the function.aws_request_id– The identifier of the invocation request.log_group_name– The log group for the function.log_stream_name– The log stream for the function instance.identity– (mobile apps) Information about the Amazon Cognito identity that authorized the request.cognito_identity_id– The authenticated Amazon Cognito identity.cognito_identity_pool_id– The Amazon Cognito identity pool that authorized the invocation.
client_context– (mobile apps) Client context that's provided to Lambda by the client application.client.installation_idclient.app_titleclient.app_version_nameclient.app_version_codeclient.app_package_namecustom– Adictof custom values set by the mobile client application.env– Adictof environment information provided by the AWS SDK.
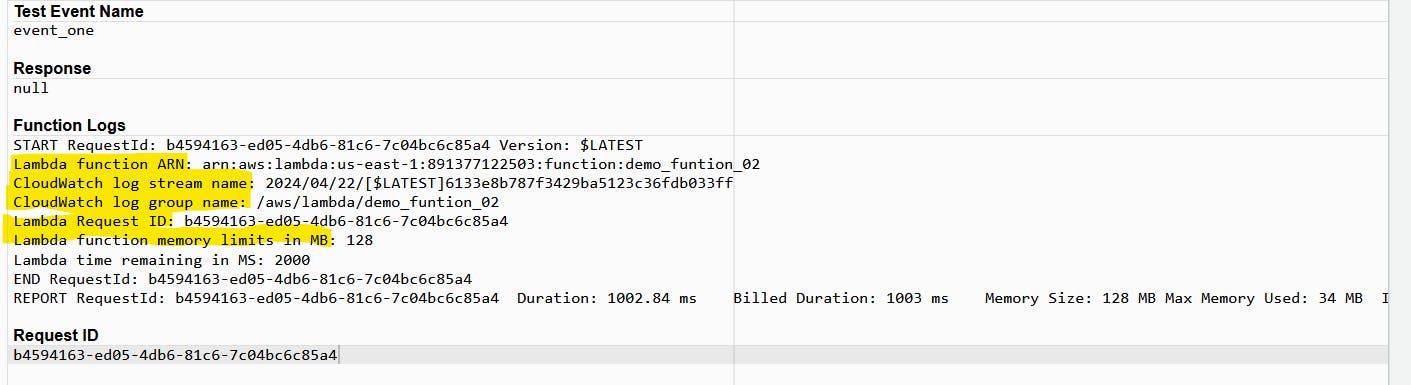
The following example shows a handler function that logs context information.
Example handler.py
import time # for adding the dely below
def lambda_handler(event, context):
print("Lambda function ARN:", context.invoked_function_arn)
print("CloudWatch log stream name:", context.log_stream_name)
print("CloudWatch log group name:", context.log_group_name)
print("Lambda Request ID:", context.aws_request_id)
print("Lambda function memory limits in MB:", context.memory_limit_in_mb)
# We have added a 1 second delay so you can see the time remaining in get_remaining_time_in_millis.
time.sleep(1)
print("Lambda time remaining in MS:", context.get_remaining_time_in_millis())
In addition to the options listed above, you can also use the AWS X-Ray SDK for Instrumenting Python code in AWS Lambda to identify critical code paths, trace their performance and capture the data for analysis.
Environment Variables
You can use environment variables to adjust your function's behavior without updating code. An environment variable is a pair of strings that is stored in a function's version-specific configuration. The Lambda runtime makes environment variables available to your code and sets additional environment variables that contain information about the function and invocation request.
Set an environment variables (console)
The Following steps explain how to set an environment variable using AWS Console:
Open-up your lambda function.
Scroll-down at code source section, And specify the configuration tab.
At the left select Environment variable, Edit for create a new one.
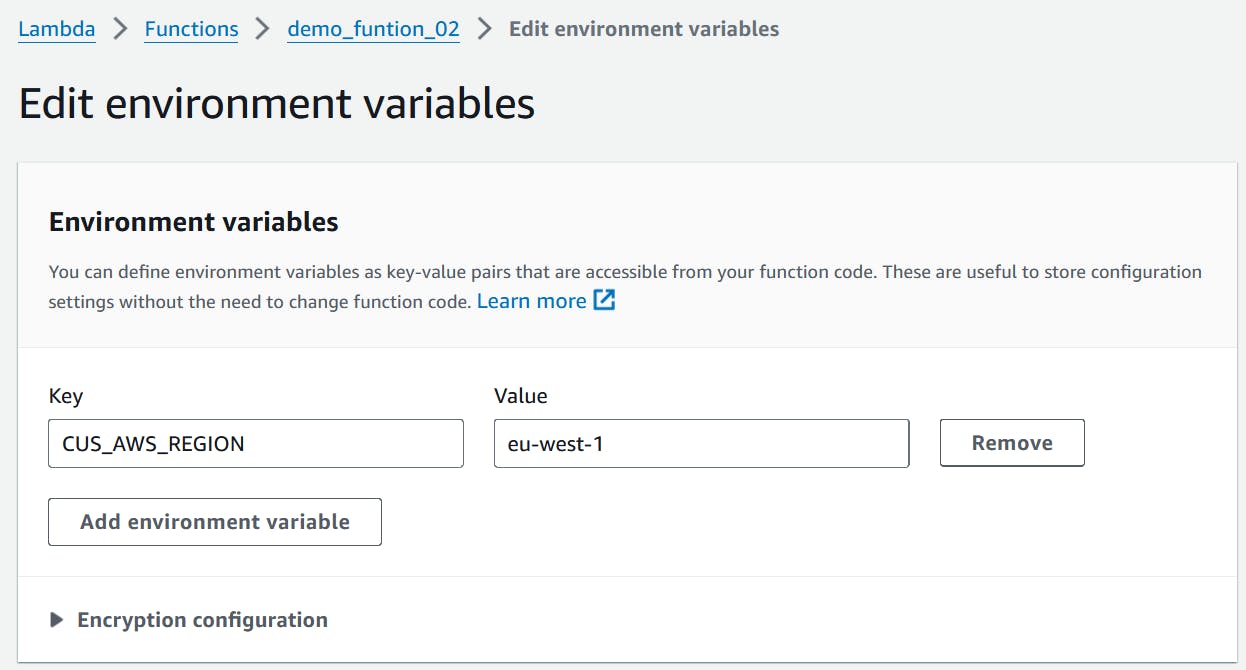
Create an environment variable holds AWS region value
Name: CUS_AWS_REGION Key: eu-west-1
Go-back to your code section and replace it with the below code.
Then deploy, Test i.e. with event don't have any pass json values - or create a new one and leave all as default -
Press Test again to invoke.
import os
import json
def lambda_handler(event, context):
reserved_envar_region = os.environ['AWS_REGION']
custom_envar_region = os.environ['CUS_AWS_REGION']
return {
"statusCode": 200,
"headers": {
"Content-Type": "application/json"
},
"body": json.dumps({
"Reserved envar Region ": reserved_envar_region,
"Custom envar Region ": custom_envar_region
})
}
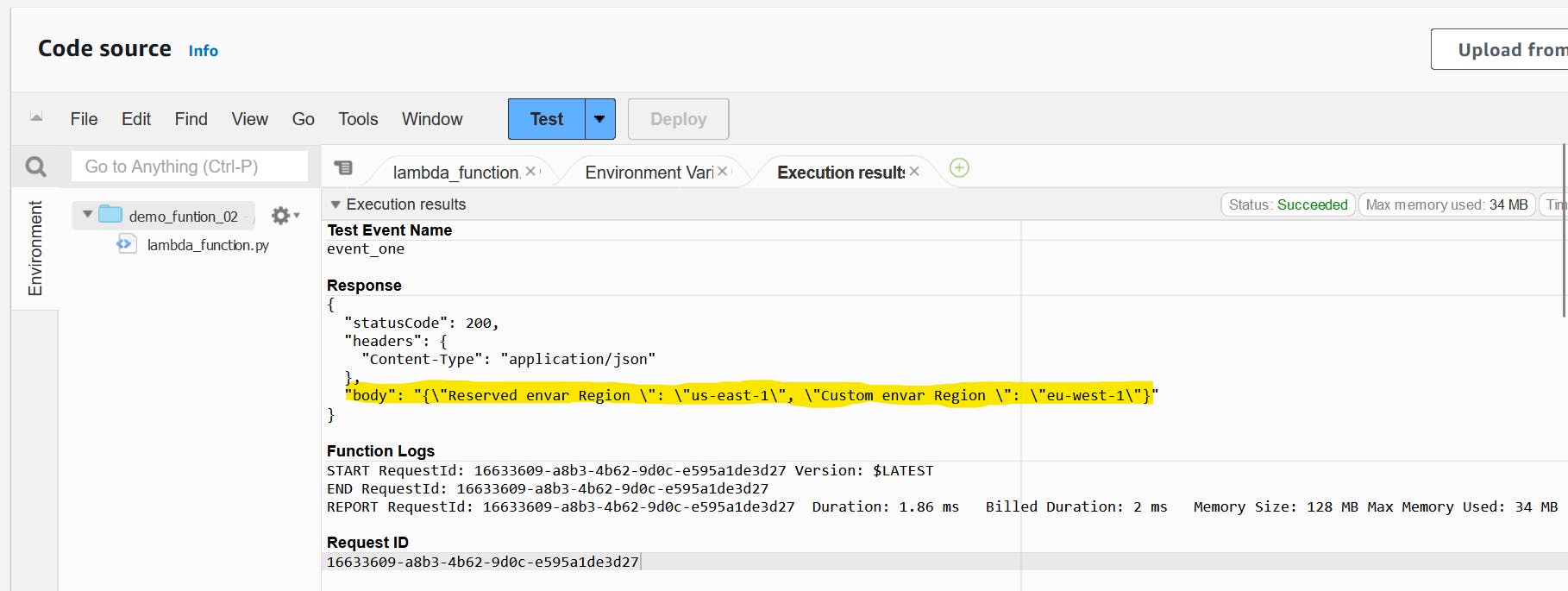
Reserved environment variables
In AWS Lambda, reserved environment variables are predefined variables that provide information about the execution environment or configuration of the Lambda function. Here are the reserved environment variables available in Lambda Python functions:
AWS_REGION: The AWS region where the Lambda function is executing.
AWS_EXECUTION_ENV: The runtime environment identifier, which includes details about the runtime environment.
AWS_LAMBDA_FUNCTION_NAME: The name of the Lambda function.
AWS_LAMBDA_FUNCTION_MEMORY_SIZE: The amount of memory allocated to the Lambda function.
AWS_LAMBDA_FUNCTION_VERSION: The version of the Lambda function.
AWS_LAMBDA_LOG_GROUP_NAME: The name of the CloudWatch Logs group where logs are streamed for the Lambda function.
AWS_LAMBDA_LOG_STREAM_NAME: The name of the CloudWatch Logs stream where logs are streamed for the Lambda function.
AWS_LAMBDA_RUNTIME_API: The base URL for the Runtime API.
AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY: AWS access key and secret access key, if the Lambda function uses IAM roles for AWS credentials.
These environment variables provide valuable information about the Lambda function's execution context and can be accessed within the function code as the example above.
Naming
The Lambda function handler name specified at the time that you create a Lambda function is derived from:
The name of the file in which the Lambda handler function is located.
The name of the Python handler function.
A function handler can be any name; however, the default name in the Lambda console is lambda_function.lambda_handler. This function handler name reflects the function name (lambda_handler) and the file where the handler code is stored (lambda_function.py).
If you create a function in the console using a different file name or function handler name, you must edit the default handler name.
Change the function handler name (console)
Open the Functions
page of the Lambda console and choose your function.
Choose the Code tab.
Scroll down to the Runtime settings pane and choose Edit.
In Handler, enter the new name for your function handler.
Choose Save.

Synchronous invocation
When you invoke a function synchronously, Lambda runs the function and waits for a response. When the function completes, Lambda returns the response from the function's code with additional data, such as the version of the function that was invoked.
Synchronous invocation is a type of function invocation in AWS Lambda where the caller waits for the function to complete execution and can receive a return value. This invocation type is suitable for short-lived Lambda functions that can run for up to 15 minutes.
When using synchronous invocation, the caller can receive a response from the Lambda function, including details about the function's execution, such as errors. The response includes a status code, which can indicate success or failure, and the execution details can be found in the function's execution log and trace.
Here are some scenarios where you might want to use synchronous invocation:
When you need to receive a return value from the Lambda function.
When you want to handle errors in the Lambda function and respond accordingly.
When you want to ensure that the Lambda function completes execution before the caller continues with other work.
It's important to note that synchronous invocation may not be suitable for long-running Lambda functions, as the client may disconnect during the invocation process. In such cases, you might want to consider using asynchronous invocation instead.
Asynchronous invocation
Several AWS services, such as Amazon Simple Storage Service (Amazon S3) and Amazon Simple Notification Service (Amazon SNS), invoke functions asynchronously to process events. When you invoke a function asynchronously, you don't wait for a response from the function code. You hand off the event to Lambda and Lambda handles the rest. You can configure how Lambda handles errors, and can send invocation records to a downstream resource such as Amazon Simple Queue Service (Amazon SQS) or Amazon EventBridge (EventBridge) to chain together components of your application.
This invocation type is suitable for long-running Lambda functions that can run for up to 15 minutes.
When using asynchronous invocation, the caller can send events to the Lambda function, but the function's execution is not blocked, and the caller does not receive a response. The function's execution details, including errors, can be found in the function's execution log and trace.
Here are some scenarios where you might want to use asynchronous invocation:
When you do not need to receive a return value from the Lambda function.
When you want to handle errors in the Lambda function and respond accordingly, but you do not need to wait for the function to complete execution.
When you want to ensure that the Lambda function can run for a longer duration without blocking the caller.
It's important to note that asynchronous invocation may not be suitable for short-lived Lambda functions, as the caller may not receive a response in a timely manner. In such cases, you might want to consider using synchronous invocation instead.
Runtime dependencies in Python
For Lambda functions that use the Python runtime, a dependency can be any Python package or module that your code depend-on. When you deploy your function using a .zip archive, you can either add these dependencies to your .zip file with your function code or use a Lambda layer. A layer is a separate .zip file that can contain additional code and other content.
The Lambda Python runtime includes the AWS SDK for Python (Boto3) and its dependencies. Lambda provides the SDK in the runtime for deployment scenarios where you are unable to add your own dependencies.
Lambda periodically updates the libraries in the Python runtime to include the latest updates and security patches. If your function uses the version of the Boto3 SDK included in the runtime but your deployment package includes SDK dependencies, this can cause version misalignment issues. For example, your deployment package could include the SDK dependency urllib3. When Lambda updates the SDK in the runtime, compatibility issues between the new version of the runtime and the version of urllib3 in your deployment package can cause your function to fail.
Fetch the boto3 version
To find out which version of the SDK for Python (Boto3) is included in the runtime you're using, Use the following script
import boto3
import botocore
def lambda_handler(event, context):
print(f'boto3 version: {boto3.__version__}')
print(f'botocore version: {botocore.__version__}')
Under the AWS shared responsibility model, you are responsible for the management of any dependencies in your functions' deployment packages. This includes applying updates and security patches.
Creating a .zip deployment package with no dependencies
Package you Python file only into a zip file If your function code has no dependencies, your .zip file contains only the .py file with your function’s handler code, Then will upload it to your lambda. Use your preferred zip utility to create a .zip file with your .py file at the root. If the .py file is not at the root of your .zip file, Lambda won’t be able to run your code, use the following bash command to zip your .py file.
zip demo_file.zip demo_file.py
Creating a .zip deployment package with dependencies
If your function code depends on additional packages or modules, you can either add these dependencies to your .zip file with your function code or use a Lambda layer. The instructions in this section show you how to include your dependencies in your .zip deployment package. For Lambda to run your code, the .py file containing your handler code and all of your function's dependencies must be installed at the root of the .zip file.
Suppose your function code is saved in a file named lambda_function.py. The following example CLI commands create a .zip file named my_deployment_package.zip containing your function code and its dependencies. You can either install your dependencies directly to a folder in your project directory or use a Python virtual environment.
Create the deployment package (project directory)
Navigate to the project directory containing your
lambda_function.pysource code file. In this example, the directory is namedmy_function.cd my_functionCreate a new directory named package into which you will install your dependencies.
mkdir package💡Note that for a.zipdeployment package, Lambda expects your source code and its dependencies all to be at the root of the.zipfile. However, installing dependencies directly in your project directory can introduce a large number of new files and folders and make navigating around your IDE difficult. You create a separatepackagedirectory here to keep your dependencies separate from your source code.Install your dependencies in the
packagedirectory. The example below installs the Boto3 SDK from the Python Package Index using pip. If your function code uses Python packages you have created yourself, save them in thepackagedirectory.pip install --target ./package boto3Create a
.zipfile with the installed libraries at the root.cd package
zip -r ../my_deployment_package.zip .This generates a
my_deployment_package.zipfile in your project directory.Add the lambda_function.py file to the root of the .zip file
cd ..
zip my_deployment_package.zip lambda_function.py
Your .zip file should have a flat directory structure, with your function's handler code and all your dependency folders installed at the root as follows.
my_deployment_package.zip
|- bin
| |-jp.py
|- boto3
| |-compat.py
| |-data
| |-docs
...
|- lambda_function.py
.py file containing your function’s handler code is not at the root of your .zip file, Lambda will not be able to run your code.Create the deployment package (virtual environment)
- Create and activate a virtual environment in your project directory. In this example the project directory is named
my_function.
~$ cd my_function
~/my_function$ python3.12 -m venv my_virtual_env
~/my_function$ source ./my_virtual_env/bin/activate
- Install your required libraries using pip. The following example installs the Boto3 SDK
(my_virtual_env) ~/my_function$ pip install boto3
- Use
pip showto find the location in your virtual environment where pip has - installed your dependencies.
(my_virtual_env) ~/my_function$ pip show <package_name>
(my_virtual_env) ~/my_function$ pip show boto3 # show info
(my_virtual_env) ~/my_function$ pip list path/to/site-package # list package content
#lib/python3.11/site-packages/
The folder in which pip installs your libraries may be named
site-packagesordist-packages. This folder may be located in either thelib/python3.xorlib64/python3.xdirectory (where python3.x represents the version of Python you are using).Deactivate the virtual environment
(my_virtual_env) ~/my_function$ deactivateNavigate into the directory containing the dependencies you installed with pip and create a
.zipfile in your project directory with the installed dependencies at the root. In this example, pip has installed your dependencies in themy_virtual_env/lib/python3.12/site-packagesdirectory.
~/my_function$ cd my_virtual_env/lib/python3.12/site-packages
~/my_function/my_virtual_env/lib/python3.12/site-packages$ zip -r ../../../../my_deployment_package.zip .
- Navigate to the root of your project directory where the .py file containing your handler code is located and add that file to the root of your .zip package. In this example, your function code file is named
lambda_function.py.
~/my_function/my_virtual_env/lib/python3.12/site-packages$ cd ../../../../
~/my_function$ zip my_deployment_package.zip lambda_function.py
Notes
.zip deployment package for Lambda is 250 MB (unzipped). Note that this limit applies to the combined size of all the files you upload, including any Lambda layers.chmod 775 <file_path>.zip file is less than 50MB, you can create or update a function by uploading the file directly from your local machine. For .zip files greater than 50MB, you must upload your package to an Amazon S3 bucket first. For instructions on how to upload a file to an Amazon S3 bucket using the AWS Management Console, see Getting started with Amazon S3. To upload files using the AWS CLI, see Move objects in the AWS CLI User Guide.Working with Lambda layers
A Lambda layer is a .zip file archive that contains supplementary code or data. Layers usually contain library dependencies, a custom runtime, or configuration files.
There are multiple reasons why you might consider using layers:
To reduce the size of your deployment packages. Instead of including all of your function dependencies along with your function code in your deployment package, put them in a layer. This keeps deployment packages small and organized.
To separate core function logic from dependencies. With layers, you can update your function dependencies independent of your function code, and vice versa. This promotes separation of concerns and helps you focus on your function logic.
To share dependencies across multiple functions. After you create a layer, you can apply it to any number of functions in your account. Without layers, you need to include the same dependencies in each individual deployment package.
To use the Lambda console code editor. The code editor is a useful tool for testing minor function code updates quickly. However, you can’t use the editor if your deployment package size is too large. Using layers reduces your package size and can unlock usage of the code editor.
The following diagram illustrates the high-level architectural differences between two functions that share dependencies. One uses Lambda layers, and the other does not.
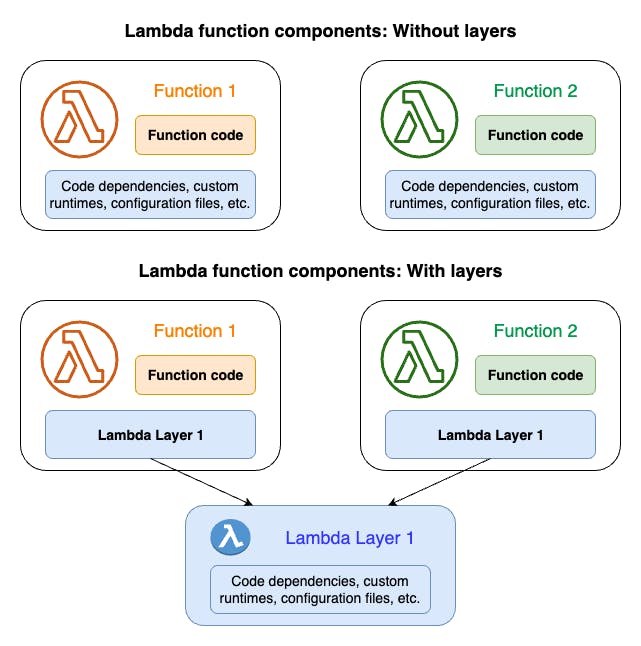
When you add a layer to a function, Lambda extracts the layer contents into the /opt directory in your function’s execution environment. All natively supported Lambda runtimes include paths to specific directories within the /opt directory. This gives your function access to your layer content.
You can include up to five layers per function. Also, you can use layers only with Lambda functions deployed as a .zip file archive. For functions defined as a container image, package your preferred runtime and all code dependencies when you create the container image.
Layer version
A layer version is an immutable snapshot of a specific version of a layer. When you create a new layer, Lambda creates a new layer version with a version number of 1. Each time you publish an update to the layer, Lambda increments the version number and creates a new layer version.
Every layer version is identified by a unique Amazon Resource Name (ARN). When adding a layer to the function, you must specify the exact layer version you want to use.
How to use layers
To create a layer, package your dependencies into a .zip file, similar to how you create a normal deployment package above. More specifically, the general process of creating and using layers involves these three steps:
First, package your layer content. This means creating a .zip file archive. For more information, see Packaging your layer content.
Next, create the layer in Lambda. For more information, see Creating and deleting layers in Lambda.
Add the layer to your function(s). For more information, see Adding layers to functions.
Accessing layer content from your function
If your Lambda function includes layers, Lambda extracts the layer contents into the /opt directory in the function execution environment. Lambda extracts the layers in the order (low to high) listed by the function. Lambda merges folders with the same name. If the same file appears in multiple layers, the function uses the version in the last extracted layer.
Dependency search path and runtime-included libraries
When you use an import statement in your code, the Python runtime searches the directories in its search path until it finds the module or package. By default, the first location the runtime searches is the directory into which your .zip deployment package is decompressed and mounted (/var/task). If you include a version of a runtime-included library in your deployment package, your version will take precedence over the version that's included in the runtime. Dependencies in your deployment package also have precedence over dependencies in layers.
When you add a dependency to a layer, Lambda extracts this to /opt/python/lib/python3.x/site-packages (where python3.x represents the version of the runtime you're using) or /opt/python. In the search path, these directories have precedence over the directories containing the runtime-included libraries and pip-installed libraries (/var/runtime and /var/lang/lib/python3.x/site-packages). Libraries in function layers therefore have precedence over versions included in the runtime.
You can see the full search path for your Lambda function by adding the following code snippet.
import sys
search_path = sys.path
print(search_path)
Lambda function logging in Python
AWS Lambda automatically monitors Lambda functions and sends log entries to Amazon CloudWatch. Your Lambda function comes with a CloudWatch Logs log group and a log stream for each instance of your function. The Lambda runtime environment sends details about each invocation and other output from your function's code to the log stream. For more information about CloudWatch Logs, see Using Amazon CloudWatch logs with AWS Lambda.
To output logs from your function code, you can use the built-in logging module. For more detailed entries.
Printing to the log
To send basic output to the logs, you can use a print method in your function. The following example logs the values of the CloudWatch Logs log group and stream, and the event object.
Example lambda_function.py
import os
def lambda_handler(event, context):
print('## ENVIRONMENT VARIABLES')
print(os.environ['AWS_LAMBDA_LOG_GROUP_NAME'])
print(os.environ['AWS_LAMBDA_LOG_STREAM_NAME'])
print('## EVENT')
print(event)
Example log output
START RequestId: 8f507cfc-xmpl-4697-b07a-ac58fc914c95 Version: $LATEST
## ENVIRONMENT VARIABLES
/aws/lambda/my-function
2023/08/31/[$LATEST]3893xmpl7fac4485b47bb75b671a283c
## EVENT
{'key': 'value'}
END RequestId: 8f507cfc-xmpl-4697-b07a-ac58fc914c95
REPORT RequestId: 8f507cfc-xmpl-4697-b07a-ac58fc914c95 Duration: 15.74 ms Billed Duration: 16 ms Memory Size: 128 MB Max Memory Used: 56 MB Init Duration: 130.49 ms
XRAY TraceId: 1-5e34a614-10bdxmplf1fb44f07bc535a1 SegmentId: 07f5xmpl2d1f6f85 Sampled: true
The Python runtime logs the START, END, and REPORT lines for each invocation. The REPORT line includes the following data:
REPORT line data fields
RequestId – The unique request ID for the invocation.
Duration – The amount of time that your function's handler method spent processing the event.
Billed Duration – The amount of time billed for the invocation.
Memory Size – The amount of memory allocated to the function.
Max Memory Used – The amount of memory used by the function.
Init Duration – For the first request served, the amount of time it took the runtime to load the function and run code outside of the handler method.
XRAY TraceId – For traced requests, the AWS X-Ray trace ID.
SegmentId – For traced requests, the X-Ray segment ID.
Sampled – For traced requests, the sampling result.
Using a logging library
logging using logging library
import os
import logging
logger = logging.getLogger()
logger.setLevel("INFO")
def lambda_handler(event, context):
logger.info('## ENVIRONMENT VARIABLES')
logger.info(os.environ['AWS_LAMBDA_LOG_GROUP_NAME'])
logger.info(os.environ['AWS_LAMBDA_LOG_STREAM_NAME'])
logger.info('## EVENT')
logger.info(event)
The output from logger includes the log level, timestamp, and request ID.
START RequestId: 1c8df7d3-xmpl-46da-9778-518e6eca8125 Version: $LATEST
[INFO] 2023-08-31T22:12:58.534Z 1c8df7d3-xmpl-46da-9778-518e6eca8125 ## ENVIRONMENT VARIABLES
[INFO] 2023-08-31T22:12:58.534Z 1c8df7d3-xmpl-46da-9778-518e6eca8125 /aws/lambda/my-function
[INFO] 2023-08-31T22:12:58.534Z 1c8df7d3-xmpl-46da-9778-518e6eca8125 2023/01/31/[$LATEST]1bbe51xmplb34a2788dbaa7433b0aa4d
[INFO] 2023-08-31T22:12:58.535Z 1c8df7d3-xmpl-46da-9778-518e6eca8125 ## EVENT
[INFO] 2023-08-31T22:12:58.535Z 1c8df7d3-xmpl-46da-9778-518e6eca8125 {'key': 'value'}
END RequestId: 1c8df7d3-xmpl-46da-9778-518e6eca8125
REPORT RequestId: 1c8df7d3-xmpl-46da-9778-518e6eca8125 Duration: 2.75 ms Billed Duration: 3 ms Memory Size: 128 MB Max Memory Used: 56 MB Init Duration: 113.51 ms
XRAY TraceId: 1-5e34a66a-474xmpl7c2534a87870b4370 SegmentId: 073cxmpl3e442861 Sampled: true
Standard JSON log outputs using Python logging library
The following example code snippet and log output show how standard log outputs generated using the Python logging library are captured in CloudWatch Logs when your function's log format is set to JSON.
Example Python logging code
import logging
logger = logging.getLogger()
def lambda_handler(event, context):
logger.info("Inside the handler function")
Example JSON log record
{
"timestamp":"2023-10-27T19:17:45.586Z",
"level":"INFO",
"message":"Inside the handler function",
"logger": "root",
"requestId":"79b4f56e-95b1-4643-9700-2807f4e68189"
}
Logging exceptions in JSON
The following code snippet shows how Python exceptions are captured in your function's log output when you configure the log format as JSON. Note that log outputs generated using logging.exception are assigned the log level ERROR.
Example Python logging code
Example Python logging code
import logging
def lambda_handler(event, context):
try:
raise Exception("exception")
except:
logging.exception("msg")
Example JSON log record
{
"timestamp": "2023-11-02T16:18:57Z",
"level": "ERROR",
"message": "msg",
"logger": "root",
"stackTrace": [
" File \"/var/task/lambda_function.py\", line 15, in lambda_handler\n raise Exception(\"exception\")\n"
],
"errorType": "Exception",
"errorMessage": "exception",
"requestId": "3f9d155c-0f09-46b7-bdf1-e91dab220855",
"location": "/var/task/lambda_function.py:lambda_handler:17"
}
Viewing logs in CloudWatch console
You can use the Amazon CloudWatch console to view logs for all Lambda function invocations.
The following provide a practical example starting with creating a lambda function holds logging configurations, Then viewing logs in CloudWatch.
The lambda function code at the following example are Fetching existing VPCs details
Create a lambda function
Open-up AWS Console, Then navigate to lambda.
Create a function with demo_logging name, and Python3.12 runtime.
Scroll-down to code section and replace the existing code with the following:
import boto3
import logging
logger = logging.getLogger()
logger.setLevel("INFO")
def lambda_handler(event, context):
ec_client = boto3.client('ec2', region_name="us-east-1")
all_available_vpcs = ec_client.describe_vpcs()
vpcs = all_available_vpcs["Vpcs"]
try:
# looping
for vpc in vpcs:
vpc_id = vpc["VpcId"]
cidr_block = vpc["CidrBlock"]
state = vpc["State"]
logger.info('## START LOGGING')
logger.info(f'VPC ID: {vpc_id} with {cidr_block} state = {state}')
logger.info('## END LOGGING')
except Exception as error:
print(f"Error occurred: {error}")
Adjust the function
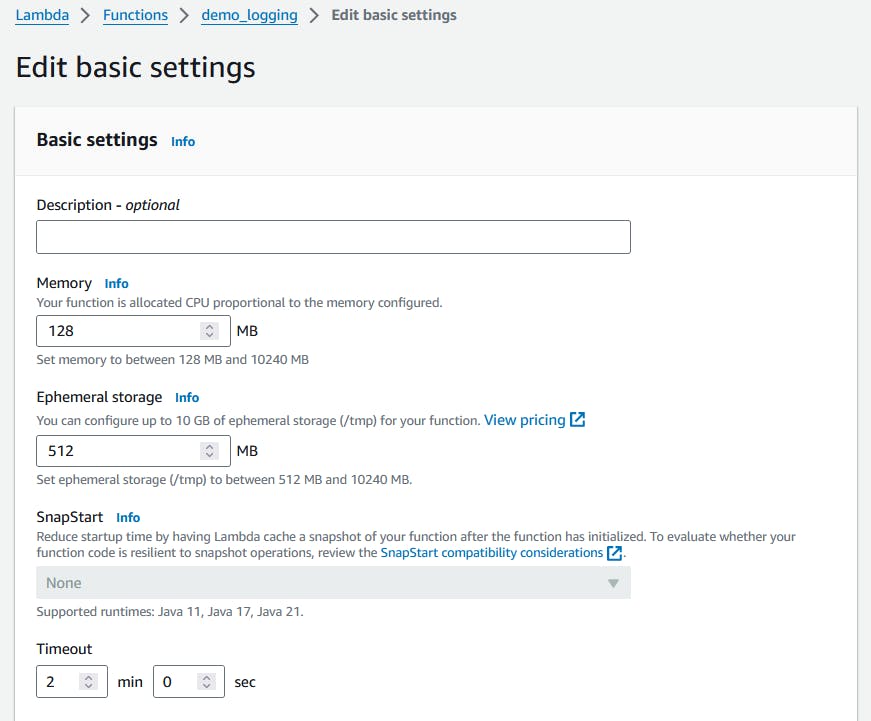
Adjust the timeout
- Specify Configuration tab, General configuration, Edit, Update the timeout as below
Append EC2 full access to Lambda Role
i.e. in order to have access on the environment execution.Navigate to IAM, Then specify Roles.
Scroll-down you find a role with your function name.
Append the EC2FullAccess policy to the lambda role.

Run the function
Navigate back to Lambda console.
Scroll-down to code source section. Then Test, type any event name, Save, And Test again.
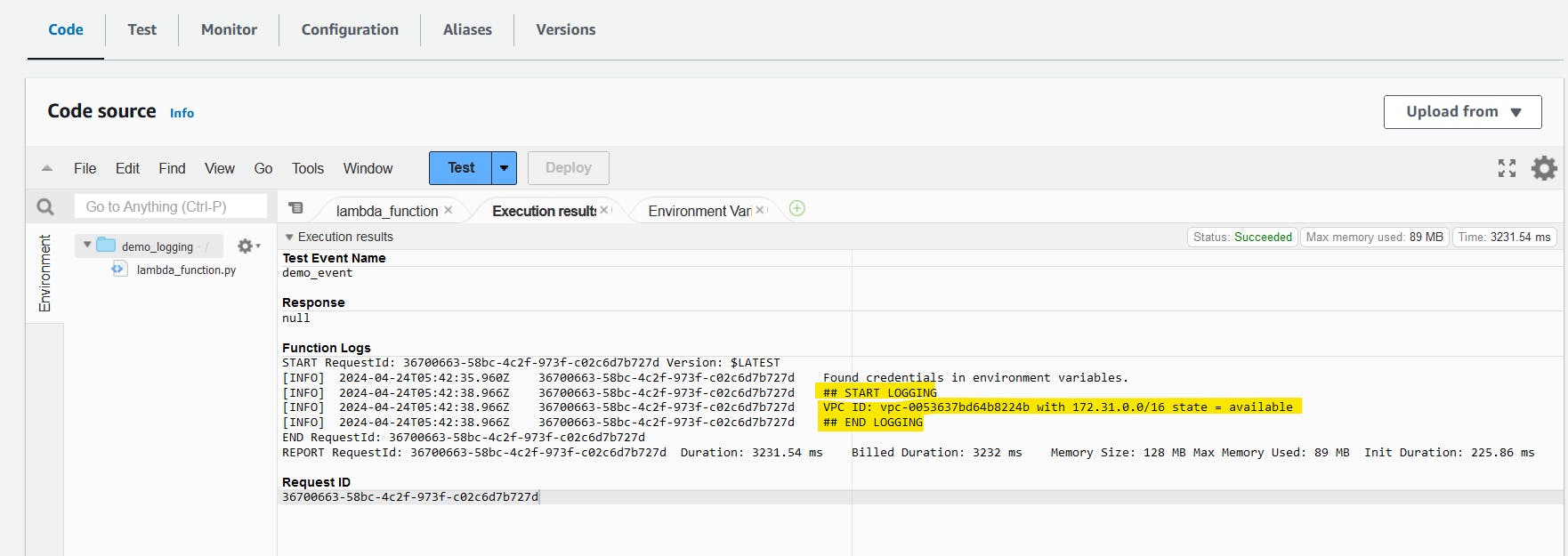
View the CloudWatch logs
Navigate to CloudWatch resource.
Under logs, log groups.
Choose the log group for your function (/aws/lambda/
your-function-name).Choose a log stream.

Scroll-down under Log Stream, Then specify the first log.
That should include our invocation details.
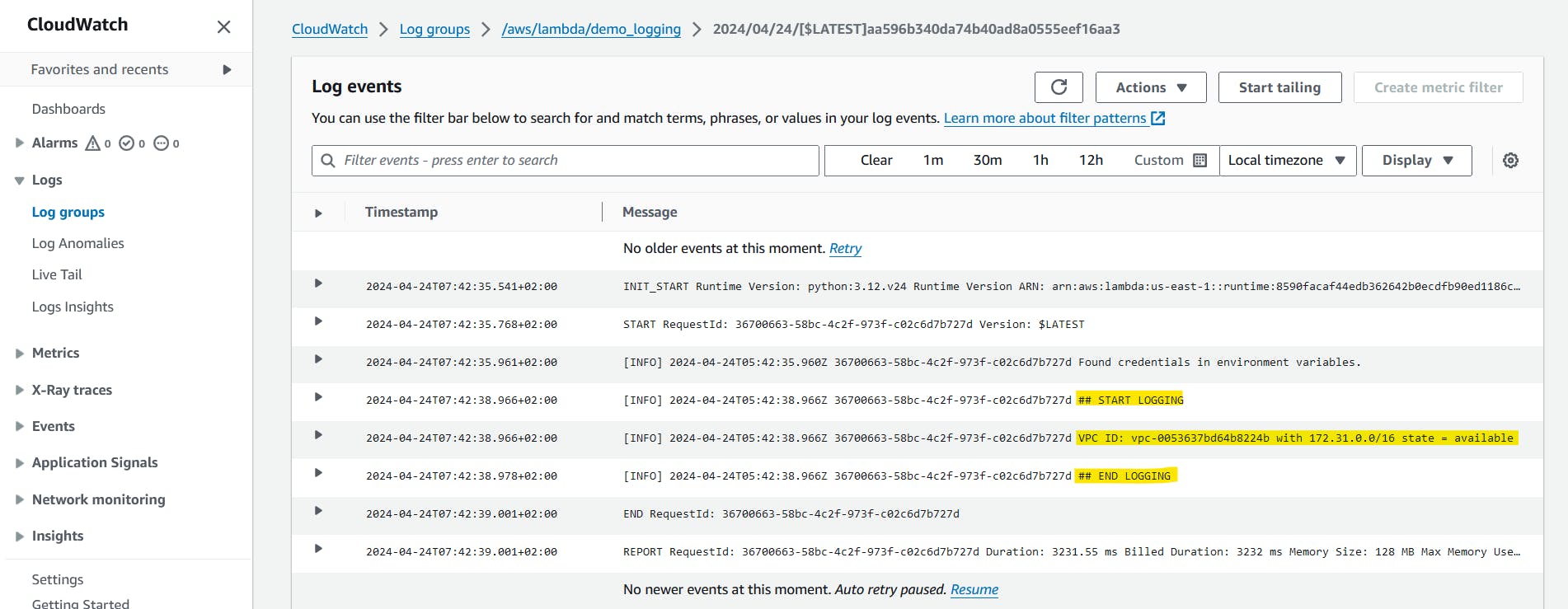
CloudWatch provides the log details of your function, Besides using log mechanism you handle and provide more information about your function in CloudWatch.
That's it, Very straightforward, very fast🚀. Hope this article inspired you and will appreciate your feedback. Thank you.